一文说明白——保险公司布局AI要关心的那些事
大模型到今天,发展到什么程度了?
跟保险有什么关系?
蒋耀锴:本轮AI的热度基本是ChatGPT之后起来的。GPT4展现出的过人的逻辑推理能力引起了新的关注高潮,逻辑推理能力标志着模型基础能力的大幅提高。
可以这么理解,曾经的初中摇身一变,跳级成了大学生。在拥有更高阶的基础能力之后,模型作为一个“大脑”还要应对社会上各种具体的工作。本质上它是缺乏经验、缺乏各种领域上下文的,那么为了让它利用好基础能力,就需要给它提供可参考的场景知识。
这就必须了解一个叫RAG的技术(retrieval augmented generation检索增强生成),它跟LLM结合在一起,是目前AI 应用落地最行之有效的路径。RAG的流行催生了不少开源项目的发展,比较重要的是Llama Index——集成了各种文档分割、索引建构、信息检索的策略以优化RAG的效果。如果AI可以参考咱们保险公司的政策、产品等资料,是可以为客户、业务员提供各种精细化服务等。
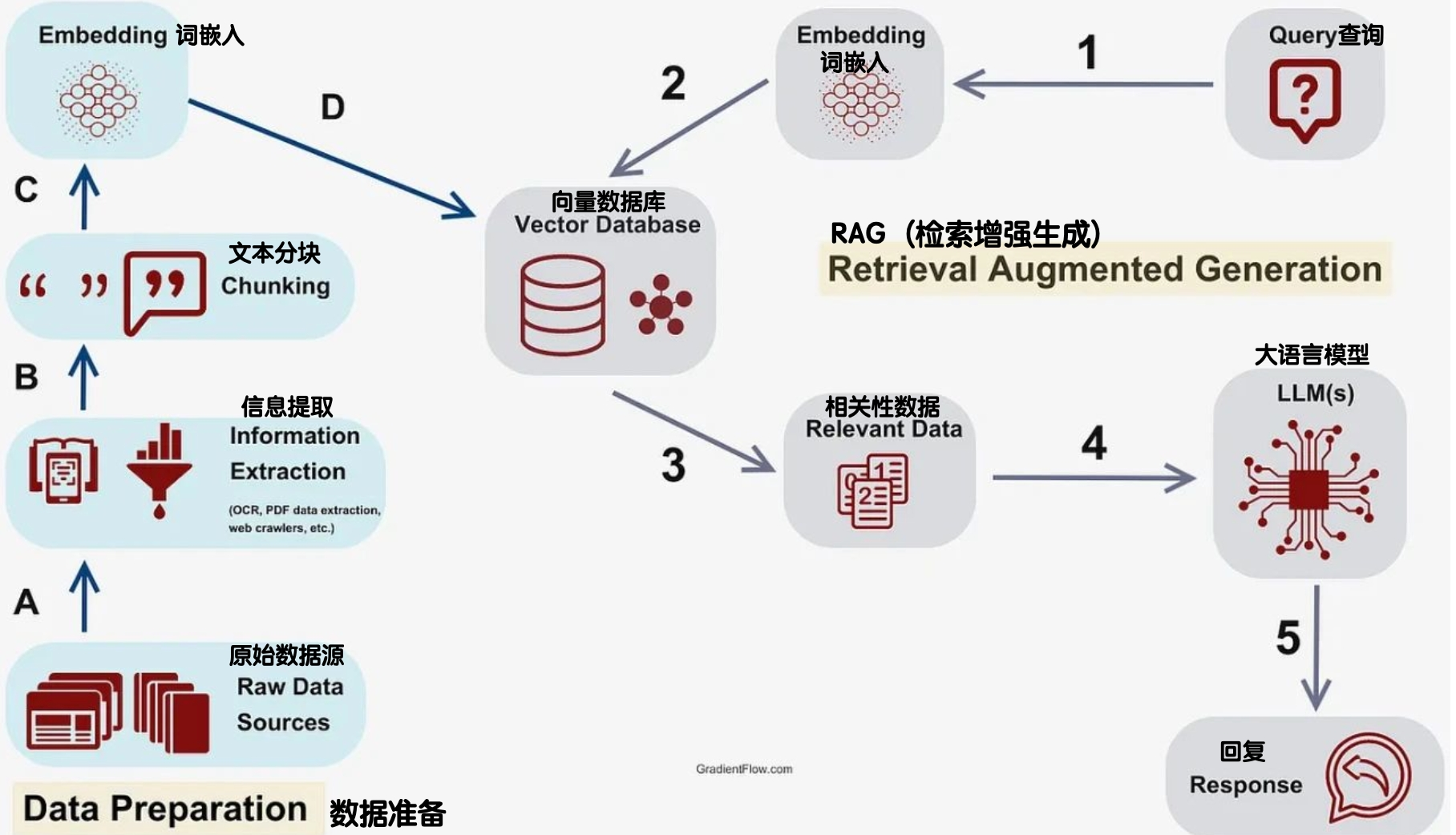
再往后,GPT 4又推出了GPT Turbo 和Vision,它们比令人津津乐道的GPTS商店要更有意义。首先,上下文窗口从GPT 4的8K变成了128K,相当于本来你只能读三页纸,现在可以读一个小本子的信息了,所能够解决问题的复杂程度不可同日而语了。举例来说,一个保险老客户出险了,这个“小本子”的空间足以支持你把客户历史记录、出险赔付的详细规则等决策参考信息都给到AI,结合GPT Vision的多模态能力,它同时有潜力读懂各种单据、车况照片上的信息。
最后一点就是,各类开源模型质量开始变得更高,开始更有现实的价值,比如Llama以及基于Llama开发的零一万物,小模型(7B或13B)的质量也在变得更好,实际上是降低了使用门槛——曾经你为了部署一个模型需要8张卡,现在只要2张卡,那么,在私有化部署上面会变得简单很多,这对保险行业来说都是颇有裨益的。
真要落地选型工作,还需要面向大模型进行考试、评分,我们内部专门设计题库和脚本对大模型的一下维度进行了测试,供参考:

在企业级场景下,AI智能体是怎样一种存在?
蒋耀锴:跟ChatGPT或者百度文心一言这类纯粹的AI Chatbot不同,Agent最大的区别是,它能自如地规划、搭建具体的工作流程。
在这个流程里面,AI可以接受和调用多个数据源的信息,并据此做决策、执行计划、观察每一步的结果,是个多步骤的事情。
不是说我问一个问题,它就直接结束了,而是说我问了一个问题,它开始制定一些计划,要分几步走,根据这几步,再把它继续拆解。Agent内在地需要调用不一样的工具,不管百度、谷歌搜索也好,用API也好,内部的数据库也好,这些都是我们需要给他提供的工具。使用了工具之后,再根据工具的反馈结果,继续执行后续的工作流,这就是一个AI智能体该有的样子。
赵赫:这里需要注意AI智能体与RPA的区别,后者的执行规则通常来说都是写死的,AI不一样,AI会不断去观察当前的状态。
大模型应用正在哪些保险场景试水?
哪些基础能力要打底?
赵赫 :在我的认知里,AI在知识搬运级别的任务上完成度比较高,它能取代的是重复性较高的一些白领工作。在保险行业中,典型的就是售后客户服务、审计校对、质检或者是核保,AI可以在外挂知识库的知识及规则补给下完成具体的任务。
但不管哪个细分AI场景要落地,都要确保先达成一些基建级别的能力。
为了提升AI应用开发的效率,最好先选定一个AI Agent框架。像我们Zion一直做前后端一体化的无代码搭建工具,今年又在此之上集成了AI的基建能力,不需要写代码就能创建自己的向量知识库,自由配置大模型,同时支持创建面向最终客户的最终页面;
另外一个非常重要的基建是数据预处理工具——目的是低成本转换出LLM- ready、RAG- ready的干净数据,尤其要让数据变成方便AI检索和消费的知识。
比如在保险的场景里,保司等要解决的问题是让AI去回复跟保险相关的内容,不得不去建立大量的知识库,这里面可能包含了保险的条款、政策,行业新闻的语料,或者是销售培训材料,这些原始文件大都是以PDF、PPT或是HTML网页文件的形态存在的,这样的数据形态,是杂乱、冗余、非结构化的,非常不利于机器理解。
我们目前在做的事情,就是把各种格式的原始文件转化统一的格式,从而让AI能够合理地调用相关信息,提升AI判断、回复或决策的质量,一个典型场景就是核保。目前我们跟新华保险上海分公司合作比较多一点,正在做的是一个服务代理人的核保工具,过往,业务员有问题需要请教核保咨询师,条款上的问题需要劳烦自己师傅,我们现在期待AI可以帮助核保的老师们回复这样繁杂的问题。
客服要建客服场景的知识库,核保要建核保场景的知识库,AI才能表现出相应的业务水准。
打个比方,我们可能在做demo或者POC的时候,里面只放了十个条款、十个病种、十个财险让他去回复,AI可能表现还不错。但如果推到五年,十年以后怎么办?仅仅寿险里面的病种类的条款就已经有5万份了,平均一份PDF三四十页,想象一下这个数据的体量还是很大的。这么多的数据要做召回,如果一开始数据解析做的不合理的话,准确率和召回率都很难保证。
我也了解到,蛮多保司保存的很多90年代的旧保单都还是纸质的,信息化水平非常有限。即便好一点,也都是以图片扫描件的方式保存的。鉴于上一代识别技术主要依赖于OCR,它对印刷文字的识别准确度非常低——像PDF里面的布局信息——比如说上下关系、左右关系,以及各种标题、段落之间的逻辑层级等都是识别不到的。那随着大模型的出现,都会有比较好的解决。
大模型赋能保险销售很受行业关注,
实践上有哪些难点?
赵赫:在中国,销售人群普遍是基于社交关系拓客和维护客户的,他们理所当然认为这是归属个人的宝贵客户资产,他们愿不愿意采用新的工具,很大程度取决于这个工具能不能把他们从重复劳动中解救出来,或者更直接提高挣钱的效率。
另外,做销售赋能不应违背该人群的沟通习惯——换句话说,不要脱离企业微信+微信的场景,像我们自己的用户社群就在逐步引入AI售后的流程,用户在企微群里就能触发AI售后助手,AI结合上下文总结出客户所指的实际问题,通过检索我们的产品知识库直接给出诊断和解决办法,AI判断解决不了的,再可以生成智能工单给到售后的同事。
还有就是认知上的卡点,我接触过很多保险从业人员,他们对大模型的预期非常两极分化,有的过于乐观,以为不需要设计合乎业务的工作流程,塞进数据就可以看着魔法生效了;有的过于悲观——万一大模型幻觉发作了怎么办,其实它跟人类一样,你的员工会不会有一定概率的犯错呢?
AI改造数字化流程中,保司要注意哪些原则?
蒋耀锴:第一,不管任何行业,在应用AI的过程中,都应该先尝试100%地去替代5%的流程,而不是一下子去替代100%的流程,就是说你要控制住这个渗透的比例,技术是始终在升级迭代的,不要一下子步子迈太大,AI技术的成熟是需要时间孕育的。
其次,适合AI做的事情,其实是还是知识搬运和合成级别的事情。目前情况下,让AI操作虚拟的东西(如知识和信息)的成本是远低于让它操控物理世界的,风险也更低。
第三,不要尝试一次性替代所有的人工。比如说历史上发生过自动化生产线代替人工生产线的事情,引入自动化生产线后,你依然会保留质量工人。那么在AI的工作流里面。我们也不完全放弃掉质检工人这种角色,这是在产品设计的时候需要考虑到的事情。
赵赫:我针对保司说说。真心认为保司没必要自己研发大模型,否则一定会入不敷出,可以看到就连我们国内的模型,也是每个阶段动辄几百个亿的投入。况且,保司上一轮数字化基础打的就不好,刚才已经提到有很多数据还停留在纸质上,大量的东西还未上云。而且保司业务系统非常多,数据都散落在各处。那么怎么在AI上面把这些数资产都利用好?重点是需要构建新的流程,这也是需要时间的。